INTRODUCTION
We at nonlinear.ai love the cloud. That said, some of our customers can’t or don’t want to use the cloud for various reasons. Nevertheless they want to use their data in the best possible way. For these cases we propose on-prem solutions which make heavy use of various open source technologies. In fact most cloud providers use the exact same technologies under the hood of their products.
Our proposal makes use of industry best practices and solutions which are considered as de facto standards. Keep in mind that this is just one possible solution. Every company's demands, prior knowledge, resources and already existing systems differ. The prefered machine learning platform should be strongly tailored towards a particular company's needs.
Technology is just one side of the coin. Engineering culture and processes play an equally important role in order to become a successful data driven company.
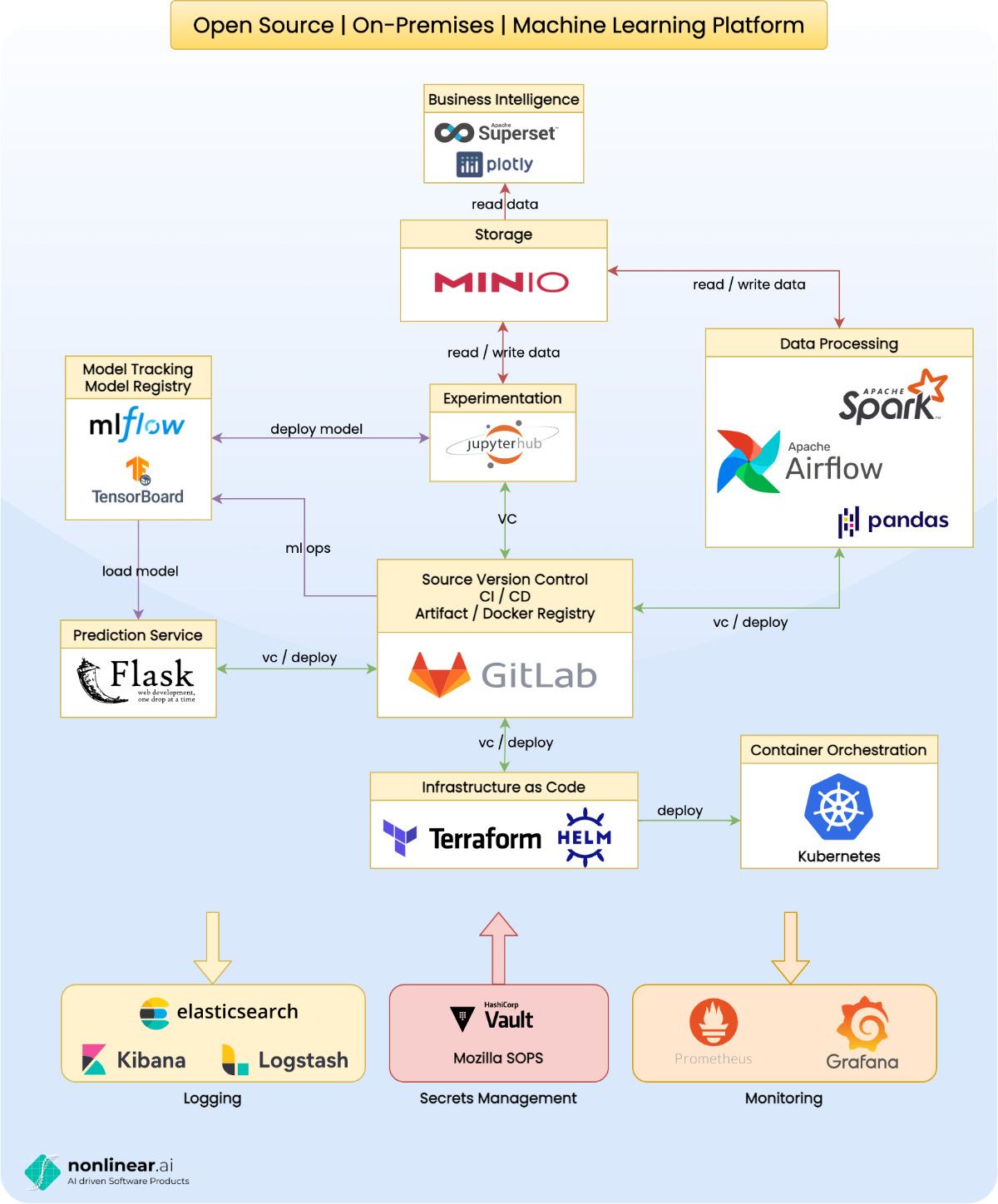
A picture is worth a thousand words so here is our on-premises open source ML platform (click to enlarge):
COMPONENTS
Below you’ll find a brief summary of the single components and how they integrate with each other. Don’t hesitate to contact us if you would like to hear more details. We’re always happy to share our experiences.
KUBERNETES FOR CONTAINER ORCHESTRATION
Setting up and maintaining all of the mentioned solutions is a lot of work. Kubernetes can help to substantially reduce this complexity. Kubernetes also simplifies setting up continuous deployment and the GitOps workflow.
GITLAB FOR SOURCE VERSION CONTROL AND CI / CD PIPELINES
Besides source version control GitLab offers pipelines to quickly setup continuous integration and continuous deployment. On top of that you get artifact repositories, container registries and environment variables. GitLab also integrates very well with Kubernetes through the GitLab Kubernetes Agent which can be used to set up a pull based GitOps workflow. You might want to have a look at Argo CD and Flux for an alternative to the GitLab Kubernetes Agent.
TERRAFORM AND HELM FOR INFRASTRUCTURE AS CODE
Infrastructure as code has many advantages. It guarantees that multiple environments such as dev, stage and prod do not diverge and can be used to spin up testing environments on the fly. It helps reduce human errors and thus increases security.
Terraform is a great tool for managing the infrastructure. It has support for all major clouds as well as providers for Kubernetes.
Helm on the other hand can be briefly described as a package manager for Kubernetes. You’ll find Helm charts for almost all popular open source products. Helm therefore substantially simplifies setting up the technologies mentioned in this article.
In combination with GitLab CI/CD pipelines both technologies can be used to implement a push based GitOps workflow.
ELASTIC STACK FOR LOGGING
All systems from APIs to machine learning models should log meaningful information. This allows us to trace down errors as well as inform us about the state of an application. The Elastic Stack centralizes logs from various systems, indexes them and makes them accessible through a nice graphical user interface.
PROMETHEUS AND GRAFANA FOR MONITORING
Applications in production need to be monitored for their health. This allows engineers to quickly act in case of or even before errors occur. Typical metrics for services are memory, disk and cpu utilization as well as access metrics such as the fraction of successful vs. faulty requests and the response latency.
Machine learning models in production need to be monitored, too. Metrics such as the fraction of positive or negative predictions or the mean and variance of feature columns help detect concept drifts and determine when to retrain a model.
Prometheus is used for collecting real time metrics which then can be visualized as dashboards in Grafana.
SOPS OR VAULT FOR SECRETS MANAGEMENT
Every application needs to handle secrets such as access credentials. For early stage companies GitLab’s environment variables may be a sufficient solution for handling those secrets.
Mozilla's SOPS is an alternative solution. It’s basically a tool to only encrypt the values of a key-value file. This makes the encrypted files still human readable and easily handable by git diff. The encrypted secrets can be stored as part of your source code and then decrypted at runtime.
For larger enterprises with more complex needs HashiCorp’s Vault may be an even better solution. It offers features such as dynamic secrets, a secret storage, identity plugins, detailed audit logs as well as the possibility to lease and revoke secrets.
JUPYTERHUB FOR EXPERIMENTATION
A data driven organization needs to be able to experiment with their data as fast as possible. Jupyter notebooks became the de facto standard for this task. JupyterHub is an extension to manage multi user usage of Jupyter notebooks.
MINIO FOR STORAGE
MinIO offers high performance object storage on Kubernetes. It’s compatible with the AWS S3 API and thus integrates well with most existing data science solutions.
MLFLOW AND TENSORBOARD FOR MODEL TRACKING
Building machine learning models means running a lot of experiments. MLFlow keeps track of used parameters and the resulting metrics of single experiments. It also acts as a model registry.
TensorBoard on the other hand can be used to monitor train metrics such as the value of the objective function over the training process.
FLASK FOR PREDICTION APIS
Flask is a “micro” web framework and can be used to write backend prediction APIs. There are many more solutions which are equally suited for writing APIs. Flask’s advantage is that it’s a Python framework: most data scientists know Python and use Python frameworks to build predictive models. Model deployment thus becomes way easier in Python than in other languages.
SUPERSET AND DASH FOR BUSINESS INTELLIGENCE
Superset is a more traditional drag and drop solution based around SQL. It’s great for creating BI dashboards and analytical tasks.
Dash on the other hand allows writing rich, interactive frontend applications only using Python. Under the hood it's using other open source frameworks such as Flask, Plotly.js and React. Dash applications can therefore be fully customized.
SPARK, PANDAS AND AIRFLOW FOR DATA PROCESSING
Spark is a distributed data processing solution. It is therefore particularly suited for big data applications which either deal with large data sizes and / or high frequency of data.
However, most companies do not deal with big data (yet). For them Pandas is a more than valid solution which can be briefly described as a Python library for data processing.
Single data processing steps are usually combined into bigger data pipelines. These data pipelines can be modeled as directed, acyclic graphs. Airflow is a great tool to manage these pipelines and provides integrations to many popular data tools.


