Summary
In this blog post we present an enterprise data architecture solely implemented in the Azure Cloud.
Introduction
Like any other major cloud provider Azure offers a wide range of products for working with data. Building up an enterprise data architecture thus becomes feasible even with a small team. Choosing which products to use and how to integrate them with each other still remains a challenging task.
Unfortunately, there is no silver bullet and the decision strongly depends on multiple factors such as the size and stage of the company, the amount, type and frequency of generated data as well as how the company is planning to use the collected data. The ideal enterprise data architecture should therefore be strongly tailored towards a particular company's needs.
We still want to share a possible setup which is quite powerful as it allows us to tackle a broad range of problems from Business Intelligence, Reporting, Analytics to Machine Learning applications.
Proposed Architecture
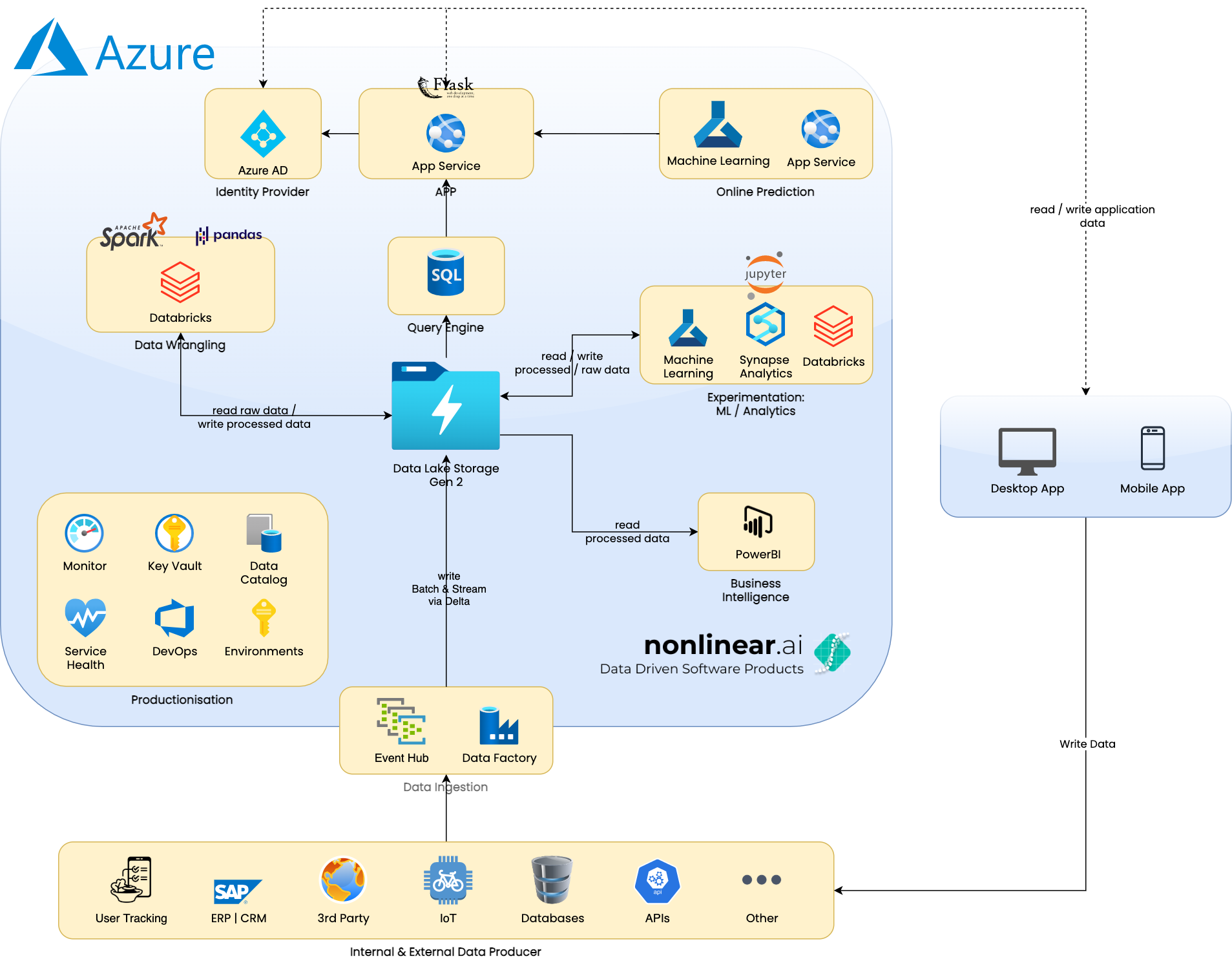
The following image shows the proposed architecture. The architecture is solely built in the Azure cloud and makes use of multiple Azure services.
Iterative Approach
The presented architecture is quite complex. However, not everything has to be set up immediately in order to use it. The implementation can be executed in an iterative approach. If for example Business Intelligence has a higher priority then only components needed for BI can be implemented first.
The devil is in the details
We can only cover a high level overview of the data architecture in this blog post. Implementing such an enterprise data architecture includes a lot of details. Some of the remaining questions are:
- Many of the used Azure services provide overlapping functionality. Which one should be used in which case?
- How to securely integrate the different Azure services?
- How to protect data from unauthorized access?
- How to automate the setup of the infrastructure?
- Which data formats to use: Parqet vs. Delta vs. Avro vs. …?
- How to structure the file hierarchy in the central storage e.g. partition keys?
- Which environments (Test, Stage, Prod) to use and how to set them up?
- Which user roles to define and what access rights to give them?
Technology is not everything
We also only cover the technical aspects here but an enterprise data architecture does not work without a good data culture (Data Governance) which among other things includes company internal roles and processes.
That's it
We hope that this blueprint helps to set up your own enterprise data architecture in Azure. The initial investment will pay off quickly as it allows to take advantage of data in all of its aspects from insights up to predictions.
Please don't hesitate to contact us if you want to learn more about the details of such an enterprise data architecture. We're always happy to share our knowledge and experience.
Components
Hereinafter we'll briefly describe the used services.
Data Factory
Data Factory provides connectors to various services such as traditional relational databases. It can be used to import data from other systems into the central data storage.
Event Hub
Event Hub can be used to ingest high frequency data such as data coming from IoT devices or user tracking data (Page Views, Clicks etc.).
Data Lake Storage Gen 2
The heart of the architecture is a Data Lake Gen 2. All data is written and read to and from this service respectively. It is a highly scalable data storage solution with fine grained access control which is especially important for security and compliance aspects such as GDPR.
Data Format
There are multiple data formats such as Parquet, Avro and Delta. Each format has its pros and cons. The choice thus highly depends on the use case.
Databricks
Databricks offers a managed Spark environment. It can be used to do all kinds of big data wrangling tasks such as data cleaning or feature generation for machine learning tasks.
Its jupyter based notebooks can also be used for ad hoc data science exploration tasks. Other tools are better suited for this task in our opinion, though.
Databricks main work horse is Spark which is particularly suited for big data wrangling. Its single node mode also allows the use of plain Pandas notebooks. This is handy for use cases which don't include big data.
Azure ML
Azure ML provides hosted jupyter notebooks on managed infrastructure. It is well suited for exploratory data science tasks. Azure ML also provides functionality to bring trained models into production. Other services might be better suited for this task though.
Synapse
Synapse tries to be the all-in-one solution for analytics tasks. Depending on the use case it might fulfill its promise but sometimes other services are a better option.
Power BI
Power BI allows you to generate rich and interactive business intelligence dashboards.
Azure AD
Azure Active Directory is a quite powerful identity management system. It is used as the central place for authentication and authorization to all of the above products.
App Service
App service can be used to implement APIs such as online machine learning prediction services.
Key Vault
Key Vault is used to handle application secrets.
DevOps
Azure DevOps is used as a version control system as well as to implement Continuous Integration, Continuous Deployment and a GitOps process.
Azure Monitor
Azure Monitor is used to monitor the performance of all systems and alert in case of system failures.
Purview / Data Catalog
It is vital for a data architecture to democratize data. This assumes discoverability and interpretability. A data catalog helps with both of these tasks.


