INTRODUCTION
When people think of data driven products they think of neural networks and deep learning. However, what people seem to forget is that the machine learning model is just a small part of a larger data architecture. The data architecture lays the foundation to work with data in the first place and enables business intelligence, analytics and machine learning models. In this post we will look into the components of an example data architecture. We’ll briefly describe each component by answering the following three questions:
1. Why do we need this component?
Here we’ll briefly answer why this component is needed and what purpose it’s serving.
2. What are desired properties of this component?
Here we’ll list main properties we’d like this component to have. If we for example have large i/o throughput then we’d like a system that’s able to handle it. If we on the other hand have lots of data we’d like a system which scales with the data. If we want real time access then the system should allow to do this.
Sometimes properties are contradicting. In other words you can’t have two things at the same time . A classical example is Brewer’s CAP theorem . In that case it’s important to chose those properties best suited for the specific use case.
3. Which products could be used for this component?
There are various products for each component and many good open source ones, too. Here we’ll mention some of them. Sometimes different solutions do almost the same thing. Sometimes they focus on different aspects of the above mentioned properties.
STREAMING VS BATCH
Data pipelines can be implemented in a batch fashion (e.g. once a day) or they can be implemented in a streaming fashion (near real time). We’ll not differentiate between those two in this post to keep things simple. Some of the tools we mention are better suited for real time whereas others are better suited for batch processing. As a rule of thumb: real time pipelines are usually more brittle and involve more work than batch pipelines.
DISCLAIMER
This post is only talking about the technological side of things. Keep in mind that a successful data organization is not only about technology. Other factors such as organizational structure, processes and people play an equally important role.
The solution shown here is just one possible data architecture. It serves as a showcase to better understand the building blocks and why we need them. Depending on the concrete use case components mentioned here might be different or completely missing.
LET’S START!
The following image shows a possible data architecture. Arrows mark the data flow direction.
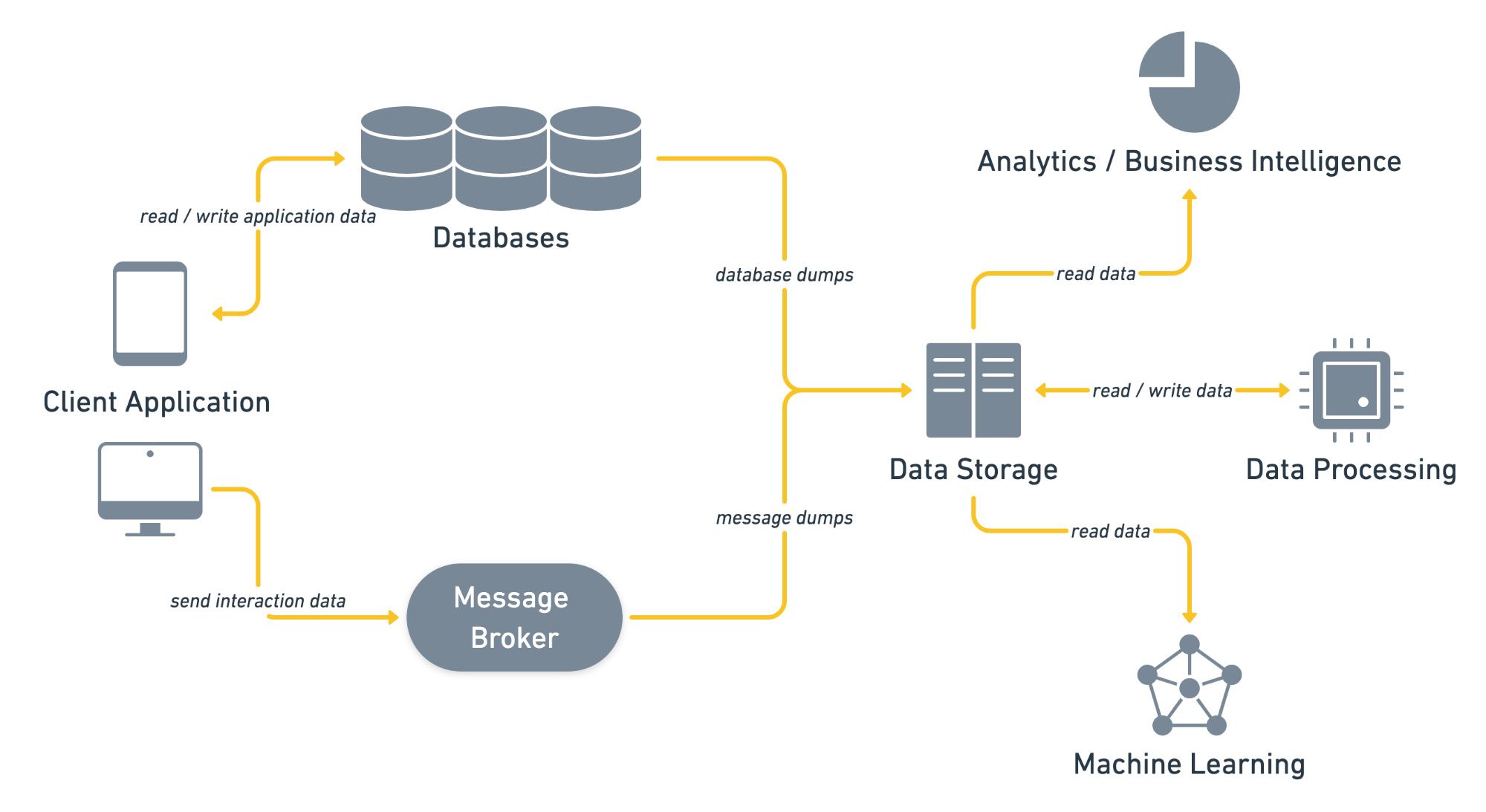
DATABASES
WHY DO WE NEED THIS COMPONENT?
Most of the available data is part of the application state e.g. user profile information, user purchases or item descriptions. This data needs to be accessible in real time and is usually stored in databases.
WHAT ARE DESIRED PROPERTIES OF THIS COMPONENT?
This highly depends on the actual use case within the application. Sometimes you want high I/O throughput. In that case NoSql databases might be a good fit. Sometimes you want to join and filter the data in various ways. In that case traditional relational databases might do the job.
WHICH PRODUCTS COULD BE USED FOR THIS COMPONENT?
Relational databases
- Postgresql
- MySql
- Mariadb
NoSQL databases
- Cassandra
- MongoDB
MESSAGE BROKER
WHY DO WE NEED THIS COMPONENT?
One key signal for many machine learning and analytical tasks are interactions users do in the app e.g. user viewed item x, user listened to song y, user read article z. This data is not part of the app state. You can imagine that an massive amount of data is produced. Every client is constantly generating data while the user is active in the app. This data will be send from client devices (Smartphone, Browser, Desktop App) to the backend. The message broker is responsible for receiving this data on the backend and routing it to multiple destinations such as real time monitoring, long term storage....
WHAT ARE DESIRED PROPERTIES OF THIS COMPONENT?
- Highly Scalable: we’re dealing with massive amounts of requests
- Asynchronous: we don’t want to block the app while sending this data. Consumers might read the data in different intervals.
- Fault Tolerant: we don’t want to lose data if a machine goes down.
- Real Time: the delay of data becoming available should be minimal
WHICH PRODUCTS COULD BE USED FOR THIS COMPONENT?
- Kafka
- AWS Kinesis
- Segment.io
DATA STORAGE
WHY DO WE NEED THIS COMPONENT?
We want to store as much data as we can. Even data which is of no use today can become so in the near future. In the past we were limited by storage space. Distributed storage models nowadays allow to store almost infinite data.
WHAT ARE DESIRED PROPERTIES OF THIS COMPONENT?
- Scalable: up to almost unlimited data
- Access restriction model: data should only be accessible by those who have a need to
- Monitored: access logs should be created and stored.
- Secure: it should be able to encrypt data at rest and transit
- Fault tolerant: data should be highly available / we don’t want to lose data
- Flexible: programming language agnostic and access pattern agnostic (batch vs. stream, ad hoc vs. production access)
WHICH PRODUCTS COULD BE USED FOR THIS COMPONENT?
- Hadoop HDFS
- AWS S3
- GCP Cloud Storage
DATA PROCESSING
WHY DO WE NEED THIS COMPONENT?
The raw data we’re collecting needs to be preprocessed. For example to generate train sets for machine learning models or derived data sets for the analytics system. This could involve simple aggregation and filtering steps e.g. group all purchases of a user and take last 100. It could also involve more complicated feature extraction steps e.g. crop and resize images.
WHAT ARE DESIRED PROPERTIES OF THIS COMPONENT?
- Highly scalable: data has to be processed on multiple machines
- Simple but flexible APIs in various programming languages
- Unit testable (please don’t use sql here :)
WHICH PRODUCTS COULD BE USED FOR THIS COMPONENT?
- Apache Spark
- Apache Beam
MACHINE LEARNING (ML) MODEL
WHY DO WE NEED THIS COMPONENT?
Machine learning models are able to learn patterns in the data and use these to predict future events. Examples are recommender systems, fraud detection and user churn prediction. The input to these models are datasets generated by the data processing step.
For some use cases predictions of the ml model are not generated in real time. Recommender systems for example might generate recommendations once a day. These recommendations need to be saved in a persistent storage from which they are served. Databases are usually used to save them.
WHAT ARE DESIRED PROPERTIES OF THIS COMPONENT?
- Scalable: we might need to train on huge datasets
- Wide adoption within the ml community: this helps finding skilled people and support.
- Pre-build / Pre-trained models: we might not want to build the models from scratch
- Good model debugging tooling
- Good deployment possibilities for inference: e.g. mobile, browser, desktop...
- Flexible: it should be able to use the same framework for most ML problems
WHICH PRODUCTS COULD BE USED FOR THIS COMPONENT?
- Pandas
- Scikit-Learn
- PyTorch
- TensorFlow
REPORTING / BUSINESS INTELLIGENCE / ANALYTICS
WHY DO WE NEED THIS COMPONENT?
AI ist just one part of dealing with data. Reporting, Business Intelligence (BI) and analytics are probably the more traditional way. Questions like:
- how many items did we sell last month?
- how many active users do we have?
- where do they live?
are answered here.
WHAT ARE DESIRED PROPERTIES OF THIS COMPONENT?
- Ability to slice and dice data to quickly find what you’re looking for
- Scalable: we’re dealing with huge datasets
- Fast: we don’t want to wait for results when browsing data
- Ability to build (interactive) dashboards
WHICH PRODUCTS COULD BE USED FOR THIS COMPONENT?
- Looker
- Tableau
- AWS Redshift / AWS QuickSight
- GCP Big Query / Data Studio
WORKFLOW MANAGEMENT SYSTEMS
WHY DO WE NEED THIS COMPONENT?
Up to now we have individual components doing one piece of work. However, we don’t want to execute these steps manually. A workflow management tool connects all these building blocks into data pipelines. One pipeline may generate trainsets using the data processing component then learn an ai model and then predict and store the results into a key value store. Another pipeline might preprocess raw data from the data storage and transfer it into the analytics system.
WHAT ARE DESIRED PROPERTIES OF THIS COMPONENT?
- Job scheduling: we want to execute pipelines on a daily, weekly … basis
- Dependency resolution: it should be able to re-trigger failed jobs together with their upstream and downstream dependencies.
- Flexible: the systems should have integrations with most of the above components
- Admin UI: it should be possible to monitor, schedule and manage workflows through an ui.
WHICH PRODUCTS COULD BE USED FOR THIS COMPONENT?
- Airflow
- Luigi
- Pinball
- Chronos
THE USUAL SUSPECTS:
This is a software project. So on top of all the things above we’d like to have some software development basics such as:
- Version Control
- Continuous Integration
- Continuous Delivery
- Logging
- Monitoring
- Alerting
UFF, THAT’S A LOT OF WORK!
Yes it is. No doubt. Luckily it’s never been easier to implement a modern data architecture. There are multiple great open source solutions which tackle the building blocks we’ve mentioned above. That said these systems are not always easy to setup and maintain. This is especially the case if they’re based on a distributed model (run on multiple machines). Luckily cloud providers offer managed solutions for many popular data architecture components. In that case you don’t have to worry about setting up and maintaining such a system. In an ideal case you just have to stick the components together.
IS IT WORTH IT?
Absolutely. A modern data architecture lays the technical foundation of a data driven organization:
- BI systems show KPIs to monitor the current state of the company at any time
- Analytics allow to base important decisions on data
- ML models help to automate existing processes, optimize services, improve products and develop completely new ones
At the end of the day making extensive use of data will give you a competitive advantage over your competitors. The big players have realized this a long time ago. Many are following them.


